
Quick answer: Choosing the right dedicated server configuration starts with the workload, not the hardware. Identify whether your application is CPU-bound, memory-bound, I/O-bound, or network-bound, then size each component (CPU, RAM, storage, network) to match the bottleneck. Add redundancy and management based on uptime requirements and team capacity. The wrong configuration costs two to four times more than the right one for the same performance.
Most people buy a dedicated server the wrong way. They open a pricing page, sort by price or CPU model, and pick something that sounds powerful enough. Six months later, they find out the box has too much CPU, not enough RAM, the wrong storage, and a network port that bottlenecks the rest. The hardware works fine. The configuration is wrong.
Configuration is where the same monthly budget can deliver two to four times the real-world performance. It all depends on whether the parts match the workload. This guide walks through the decisions in the order an experienced engineer would make them. The shortcut answer is in the reference builds section near the end. The reasoning above it is what stops the same mistake from happening twice.
If a technical term feels unfamiliar at any point, jump to the Quick Glossary of Server Terms section near the bottom. Every abbreviation in this post is defined there in plain English.
Why the Workload Decides Everything
The most useful rule in server configuration is simple. Define the workload before you open any pricing page. Every application falls into one of four bottleneck types, and the bottleneck tells you which component matters most. Get this wrong and you pay for capacity in the wrong place.
The four types are CPU-bound, memory-bound, I/O-bound, and network-bound. Most workloads sit mainly in one type, with some pressure on a second.
- CPU-bound means the processor is the limit. Video encoding, scientific computing, code compilation, and machine learning fit here. Adding RAM does nothing if the CPU is already at 100 percent.
- Memory-bound means RAM capacity or speed is the limit. In-memory databases like Redis and large caches fit here. A faster CPU does not help if the data does not fit in RAM.
- I/O-bound means storage is the limit. Busy databases, log systems, and large file processing fit here. Adding cores barely helps if the disk cannot keep up.
- Network-bound means the network port or bandwidth is the limit. Video streaming, file delivery, and CDN servers fit here. Faster storage does nothing if the network cannot push the bytes out.

A short profiling check on existing infrastructure usually reveals the main type in under an hour. Tools like htop, iostat, vmstat, and iftop on Linux show the pattern in minutes. On Windows, use Performance Monitor.
For new workloads with no existing data, the rule is to copy the bottleneck profile of a similar app. Then verify after deployment. Buying the wrong component is the most common mistake. It shows up as a server running at 15 percent CPU while the disk queue is pegged.
The Decision Sequence That Saves Money
Once the workload is clear, configuration narrows to eight decisions. Most order forms expose all eight, often hidden behind tabs. The order below matches how an engineer thinks through them, because each choice shapes the next.
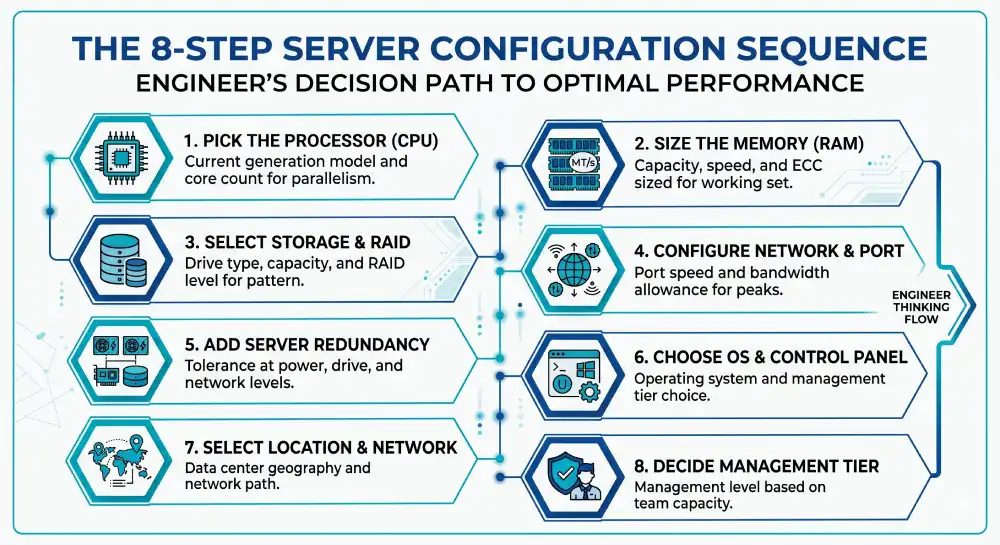
- CPU model and core count that matches the workload’s compute profile
- RAM capacity, speed, and ECC support sized for the working set plus headroom
- Storage type, capacity, and RAID level matched to the I/O pattern
- Network port speed and bandwidth allowance sized for peak transfer needs
- Redundancy at the power, drive, and network levels
- Operating system and control panel chosen for the app and team skill
- Data center location and network path that keeps latency low
- Management tier based on what the team can handle
Each decision has a sensible default for most cases, a sizing rule for common scenarios, and deeper technical knobs for unusual workloads. The sections below cover all three in one flow.
Picking the Processor: Cores vs Clock Speed
The CPU is the first decision and the one most often misunderstood. The right CPU matches your workload’s parallelism, not the highest core count on the page. Some apps scale across many cores. Others run on one thread and only care about clock speed. Buying the wrong CPU type is the most expensive form of overspending.
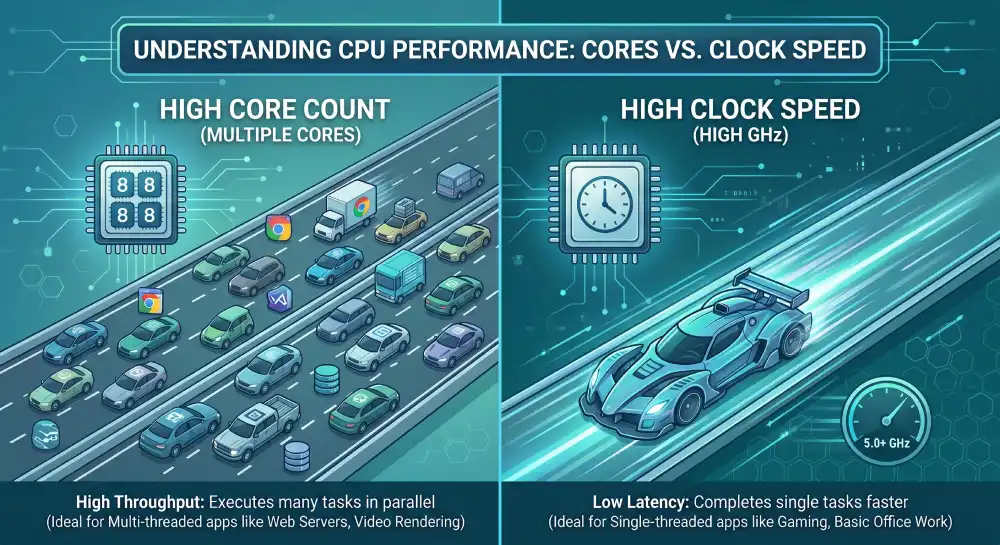
The CPU runs the instructions that make your app work. Every web request, query, and background job uses CPU cycles. A modern server CPU has multiple physical cores. Each core can run two threads at once through SMT (simultaneous multi-threading, branded as Hyper-Threading on Intel parts). More cores means more work in parallel. Higher clock speed means each task finishes faster.
For most general servers running websites, web apps, or APIs, a current CPU with 8 to 16 cores at 3.0 GHz or higher handles the workload well. Examples include the Intel Xeon Silver 4410Y, the Xeon Gold 5416S, and the AMD EPYC 8324P. These are mid-tier server CPUs in 2026, and they cover most business workloads.
The sizing rule depends on what the app does:
- Web servers and APIs: Plan for 2 to 4 cores per 1,000 active users. A site with 5,000 users needs 10 to 20 cores.
- Database servers: Match cores to concurrent connections times query complexity. PostgreSQL and MySQL want 1 core per 50 to 100 connections under normal OLTP (online transaction processing) load.
- App servers running Node.js, Python, or PHP: Each worker pins one core during a request. Provision cores equal to worker count plus 25 percent for OS overhead.
- Mixed workloads: Add the per-component needs and multiply by 1.3 for spikes.
Clock speed beats core count for single-threaded workloads. PHP-FPM, single-threaded Node.js, and many legacy apps care more about a 4.0 GHz core than a 2.5 GHz core, even if the slower CPU has twice as many cores. Always check if the app is multi-threaded before paying for parallelism. The gap between a fast few-core CPU and a slow many-core CPU can be a factor of two on the same job.
The deeper architecture choices matter too. Intel Xeon Scalable (Emerald Rapids, Granite Rapids) and AMD EPYC (Genoa, Bergamo, Turin) each have strengths. AMD usually wins on core count per socket and memory bandwidth. EPYC Genoa offers up to 96 cores per socket. Intel often wins on per-core speed and AVX-512 throughput.
L3 cache size matters a lot for databases. A CPU with 96 MB of L3 cache beats one with 32 MB on the same query workload by 15 to 30 percent. Dual-socket servers add NUMA topology, where memory access is uneven across sockets. Apps that are not NUMA-aware lose 10 to 25 percent crossing socket boundaries. Pin processes to NUMA nodes when you can, using numactl or container CPU settings.
PCIe lane count matters for storage and GPU density. EPYC offers up to 128 PCIe Gen5 lanes per socket. That counts when packing many NVMe drives or GPUs into one box. Modern EPYC parts also deliver 20 to 40 percent better performance per watt than equivalent Intel parts in 2026. That matters in colocation, where every watt is metered.
Avoid older generation CPUs unless the price gap is large. A 2020-era Xeon Gold at half the price of a current EPYC is rarely a good deal once you count the performance gap and higher power draw over a five-year lease.
Memory Sizing Without Guesswork
RAM is the second decision and the one where mistakes show up fastest. A server with too little RAM swaps to disk under load, and performance collapses by an order of magnitude. Unlike CPU, where the limit is gradual, hitting the RAM ceiling is sudden and severe.
RAM holds the data your app is working with right now. OS buffers, database caches, app memory, and connection pools all live in RAM. The more RAM you have, the more data the server holds without touching disk. Reading from RAM is about 100,000 times faster than reading from a typical SSD. That is why memory capacity drives real-world speed for most workloads.
For most general servers, 32 GB to 64 GB of DDR5 RAM is the sweet spot for business apps. Database-heavy workloads start at 64 GB. Servers running many containers or VMs often need 128 GB or more.
The sizing rule is to add the working sets of every major part, then add headroom:
- Operating system: Reserve 2 to 4 GB for Linux or 4 to 8 GB for Windows Server.
- Database buffer pool: Allocate 60 to 75 percent of total RAM to PostgreSQL
shared_buffersor MySQL InnoDB buffer pool on a dedicated database host. The pool should hold the active working set, not the whole database. - App processes: Multiply typical process memory by worker count. A Node.js process at 200 MB times 32 workers needs 6.4 GB plus headroom.
- Caching layers: Redis or Memcached should fit fully in RAM. Size the cache to the hot data set plus 20 percent.
- Headroom: Always leave 20 to 30 percent free for spikes, OS file cache, and surprises.
Here is a worked example. A server runs PostgreSQL with a 40 GB active dataset, plus a Node.js API with 32 workers at 200 MB each, plus Redis with 8 GB of cache, plus OS overhead. The math is 40 + 7 + 10 + 4 + 25 percent headroom = 76 GB minimum. Round up to 96 GB or 128 GB for safety. Going below the minimum almost always produces an unstable server within weeks.
The technical details around RAM matter more than most order forms suggest. DDR5 is the current standard in 2026. It offers 50 to 80 percent more bandwidth than DDR4 at the same capacity. Speed (4800, 5600, or 6400 MT/s) matters less than channel count. A server with 8 channels at 4800 MT/s beats 4 channels at 6400 MT/s on memory-bound work. Always populate every memory channel evenly.
ECC (Error Correcting Code) RAM is non-negotiable for production. ECC fixes single-bit errors silently and catches multi-bit errors before they corrupt data. The price gap vs non-ECC is small. The reliability gap is huge. Modern server CPUs from both Intel and AMD also need ECC for full feature support.
Registered DIMMs (RDIMMs) are standard for most servers. Load-Reduced DIMMs (LRDIMMs) allow more capacity per channel, with slightly higher latency. Choose LRDIMM only when you need more than 256 GB per socket. On dual-socket servers, balance RAM across both sockets. Asymmetric setups create performance cliffs that are hard to debug later.
The cost gap between 64 GB and 128 GB on a server lease is usually 20 to 40 USD per month. The performance gap under real load can be the difference between fast and unresponsive. Never under-spec RAM to save money. It is the most cost-effective part to over-provision.
Disk Choices That Make or Break Performance
Storage is the part where the gap between cheap and expensive options is widest. Matching the type to the workload pays off the most. The wrong storage choice can make a powerful server feel sluggish. The right one can make a modest server feel premium.
Storage holds your data when it is not in RAM. OS files, app code, databases, logs, and uploads all live on storage. The speed of storage decides how fast the server reads data not already cached. That matters every time the server starts, every time a query touches cold data, and every time a large file is moved.
Modern dedicated servers offer three main storage types. Each has a clear best fit:
- NVMe SSD is the fastest. It is ideal for databases and busy apps. Typical speeds are 3,000 to 7,000 MB per second, with sub-millisecond latency.
- SATA SSD is mid-range. It is good for general-purpose servers. Typical speeds are 500 to 600 MB per second.
- HDD (spinning disk) is the cheapest per gigabyte. It is best for backups and archives. Speeds run 100 to 200 MB per second, with much higher latency.
For any modern production workload, NVMe is the default in 2026. SATA SSD is fine for budget builds or bulk storage tiers. HDD makes sense only for cold archives, large backup targets, or media libraries where capacity per dollar matters most.
Storage has two sizing dimensions: capacity and IOPS (input/output operations per second). Most buyers think only about capacity. That is a mistake, because IOPS often runs out before space does.
For capacity, plan for current data plus growth over the contract term. Add 20 to 50 GB for OS overhead. Keep a 30 percent free buffer to keep filesystems fast. For IOPS, match storage to the workload pattern:
- OLTP databases want 50,000 to 500,000 random IOPS. NVMe is required.
- Analytics and warehousing want high sequential throughput. NVMe or fast SATA SSD both work.
- Web servers and file serving are mostly read-heavy with hot data already cached. SATA SSD is often enough.
- Backup targets want capacity, not IOPS. HDD arrays are economical here.
A common mistake is buying one large NVMe drive when two smaller drives in RAID 1 would be better. Two 1 TB NVMe drives mirrored often cost less than one 2 TB drive. And they give you both redundancy and faster reads. The single-drive setup looks cheaper on paper but creates a single point of failure that becomes a data loss event the first time the drive fails. It will fail eventually.
The technical layer of storage is where production reliability is won or lost. NVMe form factors (U.2, E1.S, M.2) differ in hot-swap support. Pick U.2 or E1.S for production servers that need hot-swap during failures. M.2 is common in smaller servers but usually needs downtime to replace.
SSD endurance is measured in DWPD (drive writes per day) or TBW (terabytes written). Database workloads need at least 1 DWPD class drives. Read-heavy workloads can use 0.3 DWPD drives at lower cost. PCIe Gen4 NVMe drives deliver around 7,000 MB per second. Gen5 doubles that to around 14,000 MB per second. Gen5 only matters if you actually saturate Gen4, which is rarer than vendors suggest.
RAID levels affect both reliability and performance. Here is a clear breakdown:
- RAID 0 stripes data for max speed with zero redundancy. Never use for production data.
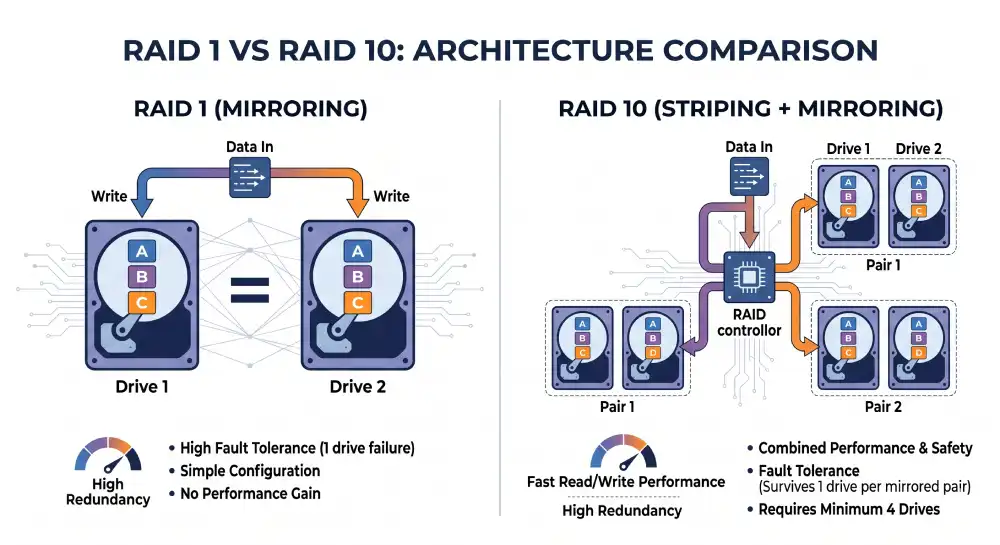
- RAID 1 mirrors data across two drives. Simple, reliable, halves usable capacity.
- RAID 5 stripes with parity across three or more drives. Good capacity but slow rebuilds. Not recommended for large modern drives. Rebuild times now run into days, and a second failure during rebuild means total data loss.
- RAID 6 stripes with double parity. Survives two drive failures. Good for large bulk arrays.
- RAID 10 mirrors and stripes for the best balance. Recommended for database servers and any workload where speed and durability both matter.
Hardware RAID controllers cost extra and add a single point of failure. They do offload work from the CPU. Software RAID using Linux mdadm or ZFS is the modern default for most workloads. It also gives better visibility when things fail.
Modern filesystems like ZFS and Btrfs add snapshots, checksums, and built-in redundancy. ZFS is excellent for database servers and storage hosts. It catches silent data corruption and supports efficient snapshots.
Always verify the storage redundancy plan before signing. A single drive with no RAID is a data loss event waiting to happen. Cheap providers sometimes default to single drives without making it clear in the configuration.
Bandwidth, Ports, and the Fine Print
The network is the part most often left at default settings. That is fine for many workloads and a disaster for others. Network sizing matters for any app that moves real data, and the bottleneck is often the bandwidth allowance rather than the port speed.
The network connects your server to the internet and to other servers. Two numbers describe network capacity. Port speed, in gigabits per second (Gbps), sets peak throughput. Bandwidth allowance, in terabytes per month, sets how much you can move before overage charges kick in.
A typical 2026 dedicated server includes a 1 Gbps port with several terabytes of monthly bandwidth. Higher tiers offer 10 Gbps, 25 Gbps, or 100 Gbps ports for high-throughput workloads.
Network sizing depends on the traffic pattern more than the app type. Calculate average traffic in Mbps from the bandwidth divided by seconds in a month: 5 TB per month equals about 15 Mbps average. Most apps have peaks 3 to 10 times the average. Plan for peaks, not averages.
Estimate monthly transfer based on visitors, page weight, and content delivery. A typical web app moves 1 to 5 MB per visitor session. A site with 100,000 monthly visitors at 3 MB each transfers 300 GB per month before overhead. Most providers meter outbound traffic and offer free or generous inbound. That means backup uploads and CDN cache fills affect outbound, not inbound.
A configuration trap to avoid is mismatching port speed and bandwidth allowance. A 1 Gbps port with a 100 TB monthly limit can saturate in less than 10 days before hitting the cap. Heavy traffic workloads need both port speed and bandwidth in proportion. The lower of the two becomes the practical ceiling.
The technical details that experienced operators care about start with port bonding. Two 10 Gbps ports bonded together using LACP give 20 Gbps total and link redundancy. Bonding is standard for production servers that need either capacity or redundancy.
Many providers offer separate ports for public internet and private inter-server traffic. Use private networking for backups, replication, and inter-server traffic to avoid metered bandwidth charges. Most providers do not bill private traffic.
IPv6 support deserves a check on the order form. Verify dual-stack support and that the provider issues a proper IPv6 subnet, usually /64 or larger. IPv6-only services are now common, and a single /128 address is not enough.
DDoS protection is the network feature that matters most on the worst day of your year. Volumetric DDoS attacks can saturate any port. Confirm what level of protection is included and what happens when an attack exceeds it. Some providers null-route the IP, taking your server offline for hours. That is exactly the wrong behavior during an attack. Better providers absorb 100 Gbps attacks without intervention.
Larger operations may want to announce their own IP space via BGP. Not all providers support this. Network latency to your users matters more for latency-sensitive apps than raw bandwidth. The route from the data center to the user is the dimension that bandwidth alone does not capture. A server with great specs in the wrong location loses to a smaller server in the right location. Anycast routing, where one IP responds from multiple locations, is offered by some providers and is worth considering for global services.
Always check the network speed at your contracted bandwidth tier. Some providers cap port speed at lower tiers and only offer full 1 Gbps or 10 Gbps on higher plans. That is the kind of detail that hides in fine print until the first heavy day reveals it.
Building in Failure Tolerance
Redundancy is the configuration choice that costs little and saves everything when something fails. Single points of failure inside a server are predictable failure modes. Adding redundancy at the right layers turns most hardware failures into non-events instead of outages.
Hardware fails. Drives fail at predictable rates that follow a bathtub curve, with higher failure in the first months and after several years. Power supplies wear out. Network cards die. Redundancy means having two of something, so the failure of one does not take the server down. A server without redundancy is a server waiting for one part to fail. The only question is when.
Three redundancy decisions matter on a dedicated server:
- Dual power supplies connected to separate power feeds in the data center
- RAID storage that survives at least one drive failure
- Bonded network ports that survive a single port or cable failure
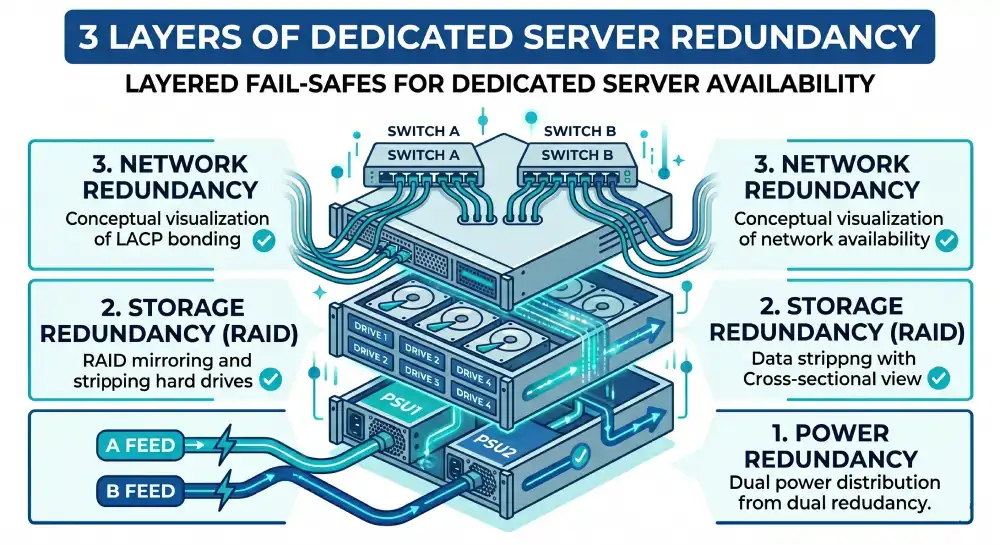
For most production workloads, all three should be standard. Skipping them saves a small amount of money and creates a real risk that surfaces unpredictably.
The implementation matters as much as the marketing claim. A server with two PSUs keeps running if one fails. But both PSUs must connect to separate PDUs (power distribution units) on separate circuits for the redundancy to be real. A dual-PSU server plugged into one PDU is not redundant against a PDU failure.
RAID configurations should match the workload. RAID 1 or RAID 10 fits performance-sensitive workloads. RAID 6 fits large bulk storage. Hot-spare drives let the array rebuild automatically when a disk fails. Network bonding only helps if the bonded ports connect to different physical switches, not the same top-of-rack switch. Otherwise, the switch becomes the single point of failure that bonding was meant to remove.
For apps that genuinely cannot tolerate downtime, server-level redundancy is not enough. You need clustering with automatic failover between physical servers. That requires at least two servers and either a load balancer or a database replication setup. Single-server redundancy reduces unplanned downtime by 70 to 90 percent for most failure modes. The remaining 10 to 30 percent needs a multi-server architecture.
The deeper layer of redundancy involves the data center itself. Verify the data center provides A and B power feeds from independent sources. Tier III and Tier IV facilities maintain runtime through grid failures using generators and UPS systems. Lower-tier facilities may not.
Hardware RAID controllers without battery-backup units (BBUs) lose their write cache contents during power loss. BBU presence is non-negotiable on hardware RAID for production databases. Out-of-band management interfaces like IPMI, iDRAC, and iLO let you reach the server when the OS is unresponsive. Always verify that out-of-band management is included and works. The day you need it is the day everything else has gone wrong. Discovering that the IPMI password was never set up turns a minor incident into a serious one.
Software Stack and Daily Operations
The OS and control panel decision affects daily operations more than any hardware choice. The right OS is the one your team can manage with confidence and the one your app is tested against. The right control panel is sometimes no control panel at all.
Modern dedicated servers run one of three OS families. Linux distributions cover the widest range of use cases. Ubuntu LTS is the default for most modern web apps. Rocky Linux and AlmaLinux fill the gap left by CentOS for enterprise compatibility. Debian remains popular for stable, conservative deployments. Fedora Server appears for teams that want recent kernel features.
Windows Server is required for ASP.NET, MSSQL Server, Exchange, and certain enterprise apps. The trade-off is higher licensing cost and heavier baseline resource use. FreeBSD and other BSDs fit a niche but excellent role for specific cases, including high-performance networking, ZFS storage hosts, and security-sensitive environments where a smaller attack surface matters.
Match the OS to the app stack. A Node.js or Python app runs better on Linux. A .NET app with Windows-only dependencies needs Windows Server. A PostgreSQL host with ZFS storage benefits from FreeBSD’s mature ZFS support. The team’s existing skill also matters. A familiar OS, managed well, outperforms an unfamiliar OS, managed poorly, every time.
Control panels add a graphical layer on top of the OS. They simplify common tasks like creating accounts, configuring email, and managing DNS. They also add license cost, expand the attack surface, and use server resources in the background.
cPanel/WHM is the industry standard for shared hosting and many dedicated servers. License costs are substantial in 2026 after years of price hikes. Plesk runs on both Linux and Windows and is strong for hosting setups that mix the two. DirectAdmin is lighter and cheaper than cPanel and is growing in popularity. Running with no control panel is the professional default for app servers, database hosts, and infrastructure managed by code.
For a single app server managed by a development team, no control panel is usually the right answer. Use SSH, configuration management like Ansible or Terraform, and direct service config for the most control and the smallest attack surface. Control panels make sense when the server hosts many independent customers, when non-technical operators need to provision sites, or when the daily workflow really benefits from a graphical interface.
Geography and Latency Math
The data center location is a configuration decision in disguise. Location decides latency to your users, compliance, and sometimes cost. A wrong choice cannot be fixed without a migration.
For latency-sensitive apps, choose the data center closest to your main users. A typical web request adds about 1 millisecond per 100 km of distance, even on optimal network paths. The speed of light in fiber is the physical limit nobody can negotiate around. A user in Sydney connecting to a server in Frankfurt sees 250 to 300 milliseconds of round-trip latency. That is enough to make interactive apps feel sluggish, no matter how fast the server is.
The location decision involves several factors beyond raw distance. User geography is the obvious one. Place the server where most users actually are, not where you happen to live. Compliance and data sovereignty often require data to stay within certain borders under GDPR, CCPA, and country-specific rules.
Network peering quality varies a lot between cities. Major Tier 1 metros like Frankfurt, Amsterdam, Ashburn, Singapore, and Tokyo offer better peering and lower latency to everywhere else. Tier 2 cities are cheaper but often slower to reach from outside the local region.
Disaster recovery geography needs the secondary site to be in a different seismic and political zone from the primary. Otherwise, a single regional event takes both sites offline at once. Local rules and content laws add another layer. Some places restrict what content can be hosted within their borders. Some require local incorporation or a local representative for hosted services. Verify these rules before committing to a location.
For most global businesses in 2026, the practical default is one primary server in a Tier 1 metro near your largest user base, plus a CDN for static content. This combination gives good latency to most users without the operational complexity of multi-region infrastructure.
Who Runs the Server Day to Day
The last configuration decision is who handles the operational work. The management tier often matters more than any hardware choice. A perfect configuration that nobody maintains becomes a broken configuration within months.
Unmanaged hosting gives you a working OS and root credentials. Everything else is the customer’s job. That includes OS patching, firewall configuration, monitoring, backups, and incident response. Unmanaged is the cheapest option and the right choice for teams with experienced sysadmins or DevOps engineers who treat the server as a real responsibility. The savings are genuine when the work happens on schedule. The flexibility is significant because no provider tooling stands between the team and the system.
Managed hosting puts the provider in charge of OS patches, security updates, monitoring setup, and basic backup config. The customer handles app-level work and architecture. Managed is the practical default for small teams that want predictable infrastructure without dedicating a sysadmin to it full-time. The cost premium is usually 30 to 100 USD per month on top of the unmanaged base. That is far less than the cost of an in-house operations engineer for the same coverage.
Fully managed hosting covers everything from OS to app support. It often includes database administration, web server config, and 24-hour incident response. Fully managed costs more, sometimes adding 100 to 500 USD per month. It pays for itself when the business cannot afford downtime and the team’s expertise is in product, not infrastructure. The best fully managed providers offer named engineers, app-level performance tuning, and proactive incident detection that most in-house teams cannot match.
A practical rule for choosing the management tier is direct. If you cannot confidently configure a Linux firewall, set up automated backups, and respond to a kernel CVE within 24 hours, do not buy unmanaged. The savings are not real if the operational work does not happen. The eventual incident costs more than years of management fees would have.
Reference Builds for Common Workloads
The component decisions become much clearer with concrete examples. The builds below match common workloads in 2026. Treat them as starting points to adjust for your traffic, growth rate, and budget.
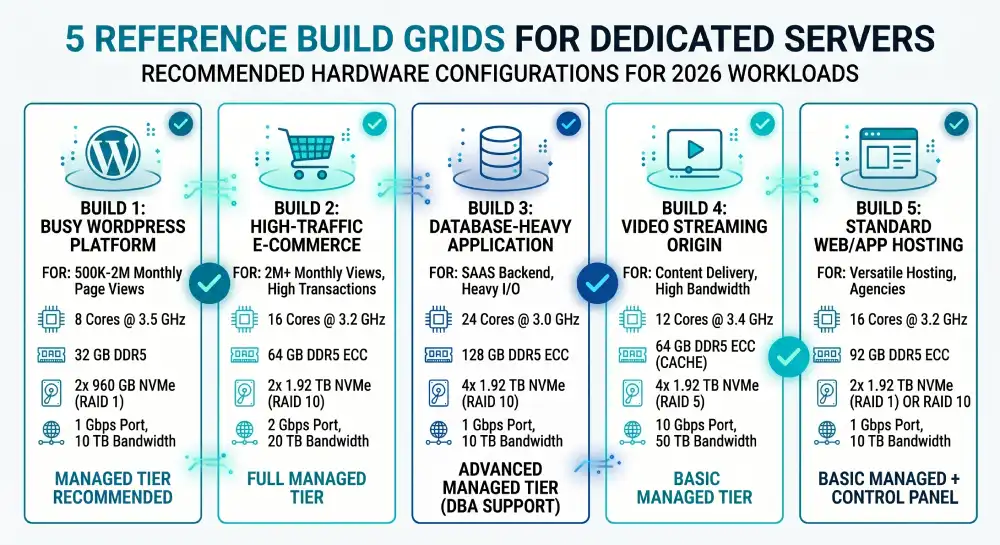
Build 1: Busy WordPress site or marketing platform
Suitable for a site doing 500,000 to 2 million monthly page views with WooCommerce or similar plugins.
- CPU: 8 cores at 3.5 GHz (Xeon Silver 4410Y or AMD EPYC 8124P)
- RAM: 32 GB DDR5 ECC
- Storage: 2 x 960 GB NVMe in RAID 1
- Network: 1 Gbps port with 10 TB monthly bandwidth
- Redundancy: Single PSU acceptable, RAID 1 storage required
- OS: Ubuntu 24.04 LTS with no control panel for technical teams, or DirectAdmin for content teams
- Management: Managed tier recommended for non-technical operators
Build 2: PostgreSQL database server
Suitable for a primary OLTP database serving a growing SaaS app.
- CPU: 16 to 32 cores at 3.0 GHz or higher with large L3 cache (AMD EPYC 9354 or Intel Xeon Gold 6534)
- RAM: 128 GB to 256 GB DDR5 ECC, sized to hold the active working set
- Storage: 4 x 1.92 TB NVMe in RAID 10 with high endurance (1 DWPD or higher)
- Network: 10 Gbps port with private networking for replication
- Redundancy: Dual PSU on separate power feeds, RAID 10 storage, hot-spare drive
- OS: Ubuntu 24.04 LTS or Rocky Linux 9, no control panel
- Management: Unmanaged for skilled DBA teams, fully managed otherwise
Build 3: Game server cluster (multiplayer FPS or similar)
Suitable for a single-region game server hosting up to 200 concurrent players.
- CPU: 8 cores at the highest available clock speed (Intel Core i9, AMD Ryzen 9, or Xeon E-class)
- RAM: 32 GB DDR5
- Storage: 1 x 960 GB NVMe (game state is typically small)
- Network: 1 Gbps port with low latency to the target user region, DDoS protection mandatory
- Redundancy: Single PSU acceptable for non-tournament environments
- OS: Linux (Ubuntu or Debian) for most modern game engines
- Management: Unmanaged with automation, given the specialized configuration
Build 4: Machine learning inference server
Suitable for serving production ML models at a moderate scale.
- CPU: 16 cores (CPU is secondary; matters mainly for preprocessing)
- RAM: 128 GB DDR5 ECC for large model loading
- GPU: 1 to 2 NVIDIA L40S, A100, or H100 cards depending on model size
- Storage: 2 x 1.92 TB NVMe in RAID 1
- Network: 10 Gbps for high-throughput inference
- Redundancy: Dual PSU on separate feeds (GPUs draw heavy power)
- OS: Ubuntu 24.04 LTS with NVIDIA drivers and CUDA stack
- Management: Unmanaged with strong MLOps tooling
Build 5: Development and CI/CD server
Suitable for build, test, and deployment automation for a small engineering team.
- CPU: 16 to 32 cores for parallel build jobs (AMD EPYC offers excellent value here)
- RAM: 64 GB DDR5 ECC
- Storage: 2 x 1.92 TB NVMe in RAID 1
- Network: 1 Gbps with generous bandwidth allowance for artifact storage
- Redundancy: Single PSU acceptable, RAID 1 storage
- OS: Ubuntu 24.04 LTS or specialized build environments
- Management: Unmanaged with infrastructure as code
These builds are starting points. Real workloads always need adjustment based on profiling data after the first few weeks. Plan for at least one resize within the first six months. The gap between predicted and actual resource use is almost always large enough to justify a tweak.
Configuration Traps Worth Avoiding
The mistakes below show up over and over in real deployments. They almost always trace back to skipping the workload analysis step at the start. Watching for them saves real money and frustration.
- Buying CPU instead of RAM. Most bottlenecks are memory-related, not CPU-related. Doubling RAM usually delivers more real-world performance than doubling cores.
- Skipping ECC memory. Non-ECC RAM in a production server invites silent data corruption. The cost difference does not justify the risk.
- Single-drive storage without RAID. A single drive is a guaranteed eventual outage. RAID 1 with two drives costs little more and removes the failure mode.
- Mismatched port speed and bandwidth allowance. A 10 Gbps port with a tiny bandwidth quota saturates in days. Match the two dimensions.
- Ignoring data center location. A great server in the wrong region delivers worse user experience than a modest server in the right one.
- Choosing unmanaged without the skills to manage. The savings are not real if the server falls behind on patches, monitoring, and backups.
- Buying for peak load year-round. Most peaks are short. Size for the 95th percentile and use caching, app-level autoscaling, or temporary capacity for genuine peaks.
- Ignoring power and cooling in colocation. A high-power server can blow out the rack power budget. Confirm power draw before ordering.
The thread across these mistakes is the same. They all come from treating server configuration as a shopping exercise instead of a workload analysis exercise. Reverse the order and most of them disappear.
Quick Glossary of Server Terms
Server hardware comes with a long list of abbreviations. This glossary covers every technical term used in this guide, in plain English. Skim it once before you read the rest, or jump back to it whenever something feels unfamiliar.
Processor and memory
- CPU (Central Processing Unit) — The main chip that runs your applications. Has multiple cores that work in parallel.
- Core — One independent processing unit inside a CPU. More cores means more work in parallel.
- Clock speed — How fast each core runs, measured in GHz. Higher means each task finishes faster.
- SMT (Simultaneous Multi-Threading) — A feature that lets one core run two tasks at once. Branded as Hyper-Threading on Intel parts.
- Hyper-Threading — Intel’s name for SMT. Same idea: one core handles two threads.
- L3 cache — High-speed memory built into the CPU itself. Larger L3 cache speeds up databases and busy queries.
- NUMA (Non-Uniform Memory Access) — In dual-socket servers, each CPU has its own memory. Crossing between them is slower. NUMA-aware apps avoid this slowdown.
- AVX-512 — A set of CPU instructions that speeds up math-heavy work like encoding and machine learning.
- PCIe (Peripheral Component Interconnect Express) — The high-speed bus that connects the CPU to drives, GPUs, and network cards. Newer generations (Gen4, Gen5) double the speed.
- PCIe lanes — Individual data channels on the PCIe bus. More lanes means more drives or GPUs can run at full speed.
- RAM (Random Access Memory) — Fast temporary memory where active data lives. Reading from RAM is roughly 100,000 times faster than from a typical SSD.
- DDR4 / DDR5 (Double Data Rate) — Generations of RAM. DDR5 is the 2026 standard and offers 50 to 80 percent more bandwidth than DDR4.
- MT/s (Mega Transfers per second) — How fast RAM moves data. Common values are 4800, 5600, and 6400 MT/s.
- DIMM (Dual Inline Memory Module) — The physical RAM stick that plugs into the server.
- RDIMM (Registered DIMM) — Standard server RAM. Adds a small buffer for stability.
- LRDIMM (Load-Reduced DIMM) — Higher-capacity server RAM. Use only when you need more than 256 GB per socket.
- ECC (Error Correcting Code) RAM — RAM that fixes single-bit errors silently and catches multi-bit errors. Required for production servers.
- Memory channel — A path between RAM and CPU. Filling all channels evenly is faster than stuffing two channels with double-capacity sticks.
Storage
- HDD (Hard Disk Drive) — Traditional spinning disk. Cheap per gigabyte, slow, best for backups and archives.
- SSD (Solid State Drive) — Flash-based storage with no moving parts. Much faster than HDD.
- SATA (Serial ATA) — An older connection type. SATA SSDs run at about 500 to 600 MB per second.
- NVMe (Non-Volatile Memory Express) — A modern protocol for SSDs that connects directly to PCIe. Speeds of 3,000 to 14,000 MB per second.
- M.2 — A small drive form factor. Common in laptops and small servers. Usually not hot-swappable.
- U.2 — A 2.5-inch enterprise NVMe form factor. Hot-swappable, suited for production servers.
- E1.S — A modern enterprise NVMe form factor for dense storage in servers. Also hot-swappable.
- IOPS (Input/Output Operations Per Second) — How many small read or write requests the storage can handle per second. Critical for databases.
- OLTP (Online Transaction Processing) — Workloads with many small, frequent database transactions, like e-commerce or banking. Needs high IOPS.
- DWPD (Drive Writes Per Day) — How many times you can fully overwrite the drive per day for the warranty period. Higher DWPD survives heavier write loads.
- TBW (Terabytes Written) — Total amount of data the drive can have written before wearing out.
- RAID (Redundant Array of Independent Disks) — Combining multiple drives for speed, redundancy, or both.
- RAID 0 — Stripes data across drives for speed. No redundancy. Never use for production data.
- RAID 1 — Mirrors data on two drives. Simple and reliable.
- RAID 5 — Stripes data with parity across three or more drives. Risky to rebuild on large modern drives.
- RAID 6 — Like RAID 5, but survives two drive failures. Good for large bulk arrays.
- RAID 10 — Mirrors and stripes drives. Fast and reliable. Recommended for databases.
- Hot-spare drive — A spare drive sitting in the server, ready to take over automatically when another drive fails.
- Hardware RAID — A dedicated controller card that manages RAID. Offloads work from the CPU.
- Software RAID — RAID handled by the OS, like Linux mdadm. Modern default for most workloads.
- mdadm — Linux’s built-in software RAID tool.
- ZFS — A modern filesystem with built-in RAID, snapshots, and silent corruption detection. Strong choice for storage hosts.
- Btrfs — Another modern filesystem with snapshots and built-in redundancy.
Network
- Gbps (Gigabits per second) — Network speed unit. A 1 Gbps port can move about 125 MB of data per second.
- Mbps (Megabits per second) — One thousandth of a Gbps. Used to describe smaller traffic levels.
- Port speed — The peak throughput of the server’s network connection.
- Bandwidth allowance — How much total data you can move per month before overage fees apply.
- Bonding (LACP, Link Aggregation Control Protocol) — Combining two network ports into one logical connection for more speed and redundancy.
- Private networking — A separate network port for server-to-server traffic. Usually not metered.
- IPv6 — The modern internet addressing system, replacing IPv4. Servers should support both.
- Subnet (/64, /128) — The size of an IP address block. /64 is a healthy IPv6 block; /128 is a single address.
- DDoS (Distributed Denial of Service) — An attack that floods your server with traffic to take it offline. Providers should absorb common attack sizes.
- Null-route — When a provider drops all traffic to your IP to stop a DDoS attack. Takes your server offline as a side effect.
- CDN (Content Delivery Network) — A network that caches your static files in many locations worldwide. Speeds up delivery and offloads bandwidth from your server.
- Anycast — A routing trick where one IP address responds from multiple locations, sending users to the nearest one.
- BGP (Border Gateway Protocol) — The protocol that routes traffic between networks on the internet. Larger operators use it to announce their own IP space.
- Latency — The delay between request and response, measured in milliseconds. Lower is better.
- Peering — Direct network connections between providers. Better peering means lower latency to other networks.
Power and management
- PSU (Power Supply Unit) — The component that powers the server. Production servers should have two for redundancy.
- PDU (Power Distribution Unit) — The rack-level power strip in the data center. Redundant PSUs should connect to separate PDUs.
- UPS (Uninterruptible Power Supply) — Battery system that keeps servers running during brief power loss until generators take over.
- BBU (Battery Backup Unit) — A small battery on a hardware RAID controller that protects cached writes during power loss.
- Tier III / Tier IV — Data center reliability ratings from the Uptime Institute. Tier III tolerates planned maintenance with no downtime; Tier IV adds full fault tolerance.
- Out-of-band management — A separate connection to the server that works even when the OS is broken.
- IPMI (Intelligent Platform Management Interface) — The generic standard for out-of-band server management.
- iDRAC (Integrated Dell Remote Access Controller) — Dell’s branded IPMI implementation.
- iLO (Integrated Lights-Out) — HPE’s branded IPMI implementation.
Operating systems and software
- OS (Operating System) — The base software that runs the server. Examples: Ubuntu, Rocky Linux, Windows Server.
- LTS (Long-Term Support) — A version of an OS that gets security updates for many years. Recommended for servers.
- Linux distribution (distro) — A specific flavor of Linux, like Ubuntu, Debian, or Rocky Linux.
- Container — A lightweight, isolated environment for running an app. Popular tools: Docker, Podman.
- VM (Virtual Machine) — A full simulated computer running inside the server.
- SSH (Secure Shell) — The standard way to log into a Linux server remotely from the command line.
- Ansible / Terraform — Tools that let you describe server configuration in code instead of clicking through panels.
- Control panel — A graphical interface for managing a server, such as cPanel, Plesk, or DirectAdmin.
- WHM (Web Host Manager) — The administrator side of cPanel.
- CUDA (Compute Unified Device Architecture) — NVIDIA’s framework for running general-purpose code on GPUs. Required for most AI workloads.
- CVE (Common Vulnerabilities and Exposures) — A public ID for a known security flaw. “Kernel CVE” means a vulnerability in the OS kernel.
Roles and workloads
- API (Application Programming Interface) — A web service that other software talks to.
- SaaS (Software as a Service) — A subscription-based web app, often hosted on dedicated infrastructure at scale.
- CI/CD (Continuous Integration / Continuous Deployment) — Automated systems that build and deploy code. CI/CD servers need many cores for parallel build jobs.
- MLOps — The operational side of running machine learning models in production.
- DBA (Database Administrator) — The person responsible for running and tuning databases.
- DevOps — A role and culture that combines software development with infrastructure operations.
- FPS (First-Person Shooter) — A type of multiplayer game. Common workload for low-latency game servers.
Compliance
- GDPR (General Data Protection Regulation) — The EU privacy law that controls how personal data is stored and processed.
- CCPA (California Consumer Privacy Act) — California’s data privacy law, similar in spirit to GDPR.
- Data sovereignty — The principle that data is subject to the laws of the country where it is stored.
If a term in this post is not in this list, it is either explained in the section where it appears or it is generic enough that a quick web search will resolve it.
Buyer Questions Answered Before You Order
How do I choose the right dedicated server configuration?
Choose the right dedicated server configuration by starting with your workload profile, not the hardware specs. Identify whether your app is CPU-bound, memory-bound, I/O-bound, or network-bound. Then size each component (CPU, RAM, storage, network) to match the main bottleneck, add redundancy for production reliability, and pick a management tier that matches your team’s capacity.
How much RAM does a dedicated server need?
A dedicated server needs 32 GB to 64 GB of RAM for general business apps, 64 GB to 128 GB for database servers, and 128 GB or more for large databases or virtualization hosts. The right amount equals the OS overhead plus the database buffer pool plus app processes plus caching, with 20 to 30 percent free as headroom for spikes.
What CPU should I choose for a dedicated server?
Choose a current generation server CPU like Intel Xeon Scalable or AMD EPYC with 8 to 16 cores at 3.0 GHz or higher for most general workloads. Pick higher core counts for parallel work like web servers and CI builds. Pick higher clock speeds for single-threaded work like legacy apps and certain database queries.
Is NVMe better than SSD for a dedicated server?
Yes, NVMe is better than SATA SSD for a dedicated server in nearly all production cases. NVMe delivers 5 to 10 times the throughput of SATA SSD and far lower latency. That matters for databases, busy web apps, and any I/O-bound workload. SATA SSD is fine only for budget builds or bulk storage tiers.
What RAID level is best for a dedicated server?
RAID 10 is the best RAID level for most production dedicated servers because it combines the speed of striping with the safety of mirroring. Use RAID 1 for two-drive setups, RAID 6 for large bulk storage that must survive two drive failures, and RAID 10 for performance-sensitive workloads like databases. Avoid RAID 5 on large modern drives.
Do I need ECC RAM on a dedicated server?
Yes, you need ECC RAM on any production dedicated server. ECC (Error Correcting Code) memory fixes single-bit errors silently and catches multi-bit errors before they corrupt data. The cost gap vs non-ECC is small. The reliability gain is significant for any app handling real data.
How much bandwidth does a dedicated server need?
A typical dedicated server needs 5 to 20 TB of monthly bandwidth for moderate web workloads, with a 1 Gbps port speed. High-traffic sites, video streaming, and CDN origins need 50 TB or more with 10 Gbps ports. Calculate based on average traffic plus peaks, and check whether the provider charges overage fees or throttles after the limit.
What operating system should I install on a dedicated server?
The best OS for a dedicated server is Ubuntu 24.04 LTS for most modern web apps, Rocky Linux or AlmaLinux for enterprise compatibility, and Windows Server only when required by app dependencies like ASP.NET or MSSQL Server. Match the OS to the app stack and to the team’s existing skill, not personal preference.
Should I use a control panel like cPanel on my dedicated server?
Use a control panel like cPanel only if you host multiple independent customers or non-technical operators need to provision sites. App servers managed by development teams should run without a control panel, using SSH and configuration management tools instead. Control panels add cost, attack surface, and resource overhead that is rarely worth it for single-app setups.
How do I size a dedicated server for a database?
Size a dedicated server for a database by allocating 60 to 75 percent of total RAM to the buffer pool, choosing NVMe storage in RAID 10 with 1 DWPD or higher endurance, and selecting a CPU with 16 to 32 cores and large L3 cache. The active working set should fit in the buffer pool whenever possible. Storage should be sized for both capacity and IOPS based on the query workload.
Putting the Configuration Together Before You Click Order
The right dedicated server configuration is the one that fits your workload at the scale you operate today, with enough room for predictable growth. Configurations chosen by copying a generic recommended build almost always cost more than they should and deliver less than they could. The build was optimized for someone else’s bottleneck.
The disciplined approach pays off year after year. Profile the workload first. Identify the bottleneck. Size each component to match. Add redundancy where production reliability requires it. Pick a management tier that matches your team. Choose a location that matches your users. Then verify the configuration after the first few weeks of operation and adjust where the real numbers differ from the predicted ones.
For anyone building their first dedicated server, the most useful guidance is also the simplest. Err on the side of more RAM, faster storage, and better redundancy. Skip CPU overspend until you have evidence you need it. Most workloads benefit from this trade in real-world performance terms. The CPU you actually need is almost always smaller than the CPU your gut says you need. The RAM and storage you actually need are almost always more.
For experienced operators, the discipline shifts. The configurations you build today will run for three to five years. The assumptions you bake in now are hard to change later. Spend the extra hour modeling the workload properly. Spend the extra week verifying provider specs against the spec sheet. Spend the extra month testing the configuration under realistic load before signing a long-term contract. The hour, the week, and the month all save more time and money than they cost over the life of the server.